 Eine empirische Analyse des US-Beispiels durch MIT-Professoren ergab, dass das Tragen von Masken zu Beginn einer Pandemie neue Fälle und die Sterblichkeit um durchschnittlich 10 Prozentpunkte senken kann. Siehe Quelle für empirische Analyse
Eine empirische Analyse des US-Beispiels durch MIT-Professoren ergab, dass das Tragen von Masken zu Beginn einer Pandemie neue Fälle und die Sterblichkeit um durchschnittlich 10 Prozentpunkte senken kann. Siehe Quelle für empirische AnalyseMask vs Covid-19
Eine empirische Analyse des US-Beispiels durch MIT-Professoren ergab, dass das Tragen von Masken zu Beginn einer Pandemie neue Fälle und die Sterblichkeit um durchschnittlich 10 Prozentpunkte senken kann. Siehe Quelle für empirische AnalyseQuelle:Jounal of Economtrics. 17.10.2020
veröffentlicht:
Normal (Gaussian) distribution
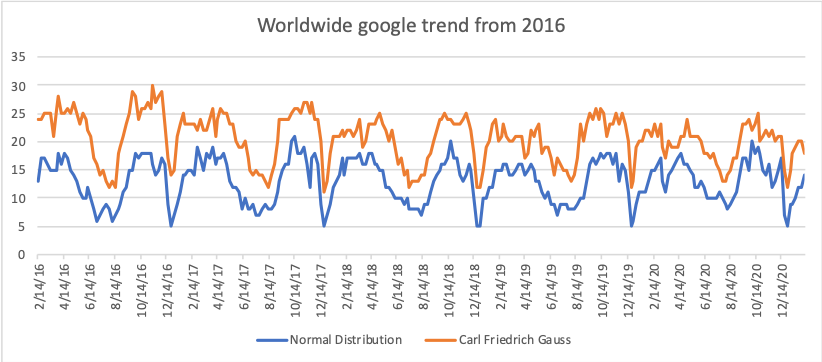 Die Normalverteilung entspricht der Gauß- Verteilung. Wenn wir uns die Statistiken der folgenden Wörter ansehen, die 2016-2020 in der Google-Suchmaschine aufgeführt sind, werden wir feststellen, dass die Suchbegriffe "Normalverteilung" und "Karl-Friedrich-Gauß-Verteilung" durch eine nahezu ähnliche Dynamik mit einem Abschluss gekennzeichnet waren Korrelation zwischen ihnen Korrelation = 0,82 Gleichzeitig erwies sich die durchschnittliche jährliche Wachstumsrate im genannten Zeitraum als positiv.
Die Normalverteilung entspricht der Gauß- Verteilung. Wenn wir uns die Statistiken der folgenden Wörter ansehen, die 2016-2020 in der Google-Suchmaschine aufgeführt sind, werden wir feststellen, dass die Suchbegriffe "Normalverteilung" und "Karl-Friedrich-Gauß-Verteilung" durch eine nahezu ähnliche Dynamik mit einem Abschluss gekennzeichnet waren Korrelation zwischen ihnen Korrelation = 0,82 Gleichzeitig erwies sich die durchschnittliche jährliche Wachstumsrate im genannten Zeitraum als positiv.Quelle:google trend
veröffentlicht:
Bestsellers in econometrics
 Die Rolle der Ökonometrie in Forschungsaktivitäten wächst, wie die modernen Herausforderungen belegen, die vom Forscher ein grundlegendes theoretisches Wissen über das Forschungsobjekt erfordern. Das Folgende ist eine Sammlung von Top-Literatur, von denen einige an den weltweit führenden Universitäten und Hochschulen als Basis- und Hilfsleitfaden erprobt und getestet wurden.
Die Rolle der Ökonometrie in Forschungsaktivitäten wächst, wie die modernen Herausforderungen belegen, die vom Forscher ein grundlegendes theoretisches Wissen über das Forschungsobjekt erfordern. Das Folgende ist eine Sammlung von Top-Literatur, von denen einige an den weltweit führenden Universitäten und Hochschulen als Basis- und Hilfsleitfaden erprobt und getestet wurden.| Der Titel des Buches | Autor |
|---|---|
| • Einführung in die Ökonometrie: Ein moderner Ansatz. Nelson Education 2015. | Jeffrey M. Wooldridge |
| • Einführung in die Bayesianische ökonometrie 2. Auflage | Edward Greenberg |
| • Ökonometrie anhand des Beispiels 2. Ausgabe | Damodar Gujarati |
| • Einführung in die Ökonometrie | Christopher Dougherty |
| • Ökonometrische Analyse von Panel-Daten 5. Ausgabe | Badi H. Baltagi |
| • Panel Data Econometrics | Donggy Sul |
| • Einführung in die ökonometrische Theorie | John Stachurski |
| • Ökonometrie für Dummies | Roberto Pedace |
| • Zeitreihenökonometrie | John D.Levendis |
| • Prinzipien der Ökonometrie, 5. Auflage | R. Carter Hill, William E. Griffths, Guay C. Lim |
veröffentlicht:
Econometric software packages
 Um ökonometrische Probleme zu lösen, stellen wir Ihnen die heute existierenden Computerprogramme vor. Die meisten von ihnen basieren auf Befehlen, deren Beschwörung eine bestimmte Aufgabe erledigt. Nachfolgend finden Sie eine Liste der Top-Programme, die sich durch unterschiedliche Funktionen voneinander abheben. Dazu gehören: Aufgabenqualität, Zugänglichkeit und visuelle Interpretation der Daten
Um ökonometrische Probleme zu lösen, stellen wir Ihnen die heute existierenden Computerprogramme vor. Die meisten von ihnen basieren auf Befehlen, deren Beschwörung eine bestimmte Aufgabe erledigt. Nachfolgend finden Sie eine Liste der Top-Programme, die sich durch unterschiedliche Funktionen voneinander abheben. Dazu gehören: Aufgabenqualität, Zugänglichkeit und visuelle Interpretation der Daten| Software | Webadresse |
|---|---|
| • R and RStudio | Gehe zum Link_1,Gehe zum Link_2 |
| • Python | Gehe zum Link |
| • SAS | Gehe zum Link |
| • SPSS | Gehe zum Link |
| • MATLAB | Gehe zum Link |
| • Eviews | Gehe zum Link |
| • Stata | Gehe zum Link |
| • Excel | Gehe zum Link |
| • GAUSS | Gehe zum Link |
| • OriginLab | Gehe zum Link |
| • Prism | Gehe zum Link |
| • Minitab | Gehe zum Link |
veröffentlicht:
Regression analysis in Excel
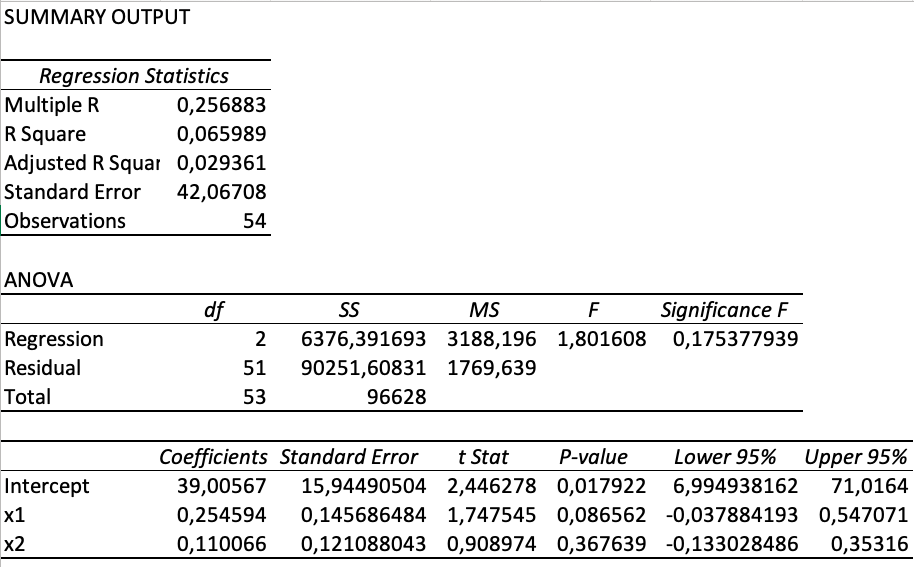 Excel ist als das bekannteste und universellste Programm zur Datenverarbeitung und -interpretation bekannt. Excel kann diese oder jene komplexe Aufgabe problemlos bewältigen. Für die Regressionsanalyse verwendet Excel das Regressionsmodell der Methode der kleinsten Quadrate (OLS), das uns sofort das Ergebnisfeld liefert. Es enthält ökonometrische Indikatoren wie den Bestimmungskoeffizienten, die Standardabweichung der Koeffizienten und die übrigen Basisindikatoren.
Excel ist als das bekannteste und universellste Programm zur Datenverarbeitung und -interpretation bekannt. Excel kann diese oder jene komplexe Aufgabe problemlos bewältigen. Für die Regressionsanalyse verwendet Excel das Regressionsmodell der Methode der kleinsten Quadrate (OLS), das uns sofort das Ergebnisfeld liefert. Es enthält ökonometrische Indikatoren wie den Bestimmungskoeffizienten, die Standardabweichung der Koeffizienten und die übrigen Basisindikatoren.Regressionsanalyse, Anweisungen und Erklärungen aktivieren
Optionen - Analyse-ToolPak - Analyse-ToolPak prüfen
Nach Aktivierung von Analysis ToolPak geben wir Data - Analysis - Regression ein
Füllen Sie den Bereich unabhängiger Y- und abhängiger X-Variablen aus. Durch Drücken der Eingabetaste wird das resultierende Feld angezeigt. Wie auf dem Foto gezeigt.
| • Multiple R | Mehrfachkorrelationskoeffizient |
| • R Square | Bestimmungsrate |
| • Adjusted R Square | Korrigierte Bestimmungsrate |
| • Standard Error | Standardfehler |
| • Observations | Beobachtung |
| • ANOVA | Varianzanalyse |
| • Regression | Regression |
| • Residual | Residuum |
| • Total | Gesamt |
| • df | Freiheitsgrade |
| • SS | Summe der Quadrate |
| • MSS | mittleres Quadrat |
| • F | Fischerstatistik - MSregression / MSresidual |
| • Significance F | Signifikanz der Regression |
| • Intercept | Free Ratio |
| • Coefficients | Regressionskoeffizienten |
| • t Stat | Studentenstatistik |
| • P-value | Wahrscheinlichkeit, dass Regressionskoeffizienten mit theoretischen Koeffizienten übereinstimmen |
| • Lower 95% | Untergrenze der Regressionskoeffizienten |
| • Upper 95% | Obergrenze der Regressionskoeffizienten |
veröffentlicht:
AI, BI and Microsoft Power Apps.
 Microsoft ist führend in der Entwicklung künstlicher Intelligenz. Sie können die moderne Methode der Datenverarbeitung und -interpretation verwenden, bei der künstliche Intelligenz bei der Datenanalyse verwendet wird. Aufgrund der Tatsache, dass für die Aktivitäten in diesem oder jenem Bereich eine angepasste Plattform erforderlich ist, können mit Hilfe von Microsoft Power Apps Modelle erstellt werden, die für die jeweilige Aktivität spezifisch sind, und zwar in Form von Anwendungen, die der Benutzer erstellt und das gewünschte Steuerelement festlegt Panel mit Low-Code. Die KI mit künstlicher Intelligenz ist eine universelle Möglichkeit, diese oder jene Aufgabe vollständig computergestützt zu lösen. Für Unternehmen ist es so wichtig, dass Microsoft ein Power BI-Programm (Business Intelligence) erstellt hat, das künstliche Intelligenz zur Visualisierung und Verarbeitung von Daten verwendet.
Microsoft ist führend in der Entwicklung künstlicher Intelligenz. Sie können die moderne Methode der Datenverarbeitung und -interpretation verwenden, bei der künstliche Intelligenz bei der Datenanalyse verwendet wird. Aufgrund der Tatsache, dass für die Aktivitäten in diesem oder jenem Bereich eine angepasste Plattform erforderlich ist, können mit Hilfe von Microsoft Power Apps Modelle erstellt werden, die für die jeweilige Aktivität spezifisch sind, und zwar in Form von Anwendungen, die der Benutzer erstellt und das gewünschte Steuerelement festlegt Panel mit Low-Code. Die KI mit künstlicher Intelligenz ist eine universelle Möglichkeit, diese oder jene Aufgabe vollständig computergestützt zu lösen. Für Unternehmen ist es so wichtig, dass Microsoft ein Power BI-Programm (Business Intelligence) erstellt hat, das künstliche Intelligenz zur Visualisierung und Verarbeitung von Daten verwendet.veröffentlicht:
ML (Machine Learning) - Learn and teach
 In der Welt der digitalen Industrie nimmt maschinelles Lernen einen wichtigen Platz ein. Sie können damit Aufgaben ausführen, für die nur wenige Informationen vorliegen. ML (Machine Learning) kann eine neue Variable für eine neue Funktion erstellen, die benannt werden muss. Angesichts der Tatsache, dass der Algorithmus einen Teil der Mathematik der Wahrscheinlichkeitstheorie aktiv verwendet, kann man vermuten, dass das von ML erzielte Ergebnis auch probabilistisch ist, aber der Algorithmus kann in Betracht ziehen, Fehler zu minimieren und den Prozess fortzusetzen, bis das Ergebnis zuverlässig und vollständig ist. Aufgrund dieser Merkmale versuchen Unternehmen in der digitalen Industrie aktiv, maschinelles Lernen in Anwendungen oder Computerprogrammen einzuführen. Es ist jedoch zu beachten, dass für die Erstellung des anfänglichen Algorithmus gründliche Kenntnisse der Mathematik erforderlich sind, da alle Informationen in die Computersprache übersetzt werden und umgekehrt gibt uns der Computer neue Variablen Ressource. Letzteres gibt uns ein sehr wichtiges Ergebnis über dieses oder jenes Ereignis.
In der Welt der digitalen Industrie nimmt maschinelles Lernen einen wichtigen Platz ein. Sie können damit Aufgaben ausführen, für die nur wenige Informationen vorliegen. ML (Machine Learning) kann eine neue Variable für eine neue Funktion erstellen, die benannt werden muss. Angesichts der Tatsache, dass der Algorithmus einen Teil der Mathematik der Wahrscheinlichkeitstheorie aktiv verwendet, kann man vermuten, dass das von ML erzielte Ergebnis auch probabilistisch ist, aber der Algorithmus kann in Betracht ziehen, Fehler zu minimieren und den Prozess fortzusetzen, bis das Ergebnis zuverlässig und vollständig ist. Aufgrund dieser Merkmale versuchen Unternehmen in der digitalen Industrie aktiv, maschinelles Lernen in Anwendungen oder Computerprogrammen einzuführen. Es ist jedoch zu beachten, dass für die Erstellung des anfänglichen Algorithmus gründliche Kenntnisse der Mathematik erforderlich sind, da alle Informationen in die Computersprache übersetzt werden und umgekehrt gibt uns der Computer neue Variablen Ressource. Letzteres gibt uns ein sehr wichtiges Ergebnis über dieses oder jenes Ereignis.veröffentlicht:
Econometric Society Online
 Die Popularisierung der ökonometrischen Forschung wird seit dem letzten Jahrhundert von der ökonometrischen Gemeinschaft aktiv vorangetrieben. www.econometricsociety.org organisiert Meetings, veröffentlicht Zeitschriften und ermöglicht Forschern, ihre Ergebnisse mit der Öffentlichkeit zu teilen. Es sei darauf hingewiesen, dass die Wirtschaftsgemeinschaft Sonderpreise in verschiedenen Nominierungen hat, die an den Autor des besten Papiers vergeben werden.
Die Popularisierung der ökonometrischen Forschung wird seit dem letzten Jahrhundert von der ökonometrischen Gemeinschaft aktiv vorangetrieben. www.econometricsociety.org organisiert Meetings, veröffentlicht Zeitschriften und ermöglicht Forschern, ihre Ergebnisse mit der Öffentlichkeit zu teilen. Es sei darauf hingewiesen, dass die Wirtschaftsgemeinschaft Sonderpreise in verschiedenen Nominierungen hat, die an den Autor des besten Papiers vergeben werden.veröffentlicht:
Nobel Prize 1901 - 2020
 Der Anteil der Nobelpreisträger im Bereich Wirtschaft ist im Vergleich zu anderen Bereichen gering. Zwischen 1901 und 2020 machte es nur 9% der gesamten Preisnominierungen aus. In den Naturwissenschaften erreichte die Zahl der Preisträger im genannten Zeitraum insgesamt 37%. Es sollte beachtet werden, dass der Nobelpreis für Wirtschaftswissenschaften ziemlich schwer zu verdienen ist, da eine bestimmte wissenschaftliche Arbeit mit allen akademischen Kriterien in das wirkliche Leben passen muss und universelle Vorteile für zukünftige Generationen haben muss. Eine solche Innovation kann jedes Wirtschaftsmodell sein, das löst soziale Probleme wie Arbeitslosigkeit auf hohem Niveau.
Der Anteil der Nobelpreisträger im Bereich Wirtschaft ist im Vergleich zu anderen Bereichen gering. Zwischen 1901 und 2020 machte es nur 9% der gesamten Preisnominierungen aus. In den Naturwissenschaften erreichte die Zahl der Preisträger im genannten Zeitraum insgesamt 37%. Es sollte beachtet werden, dass der Nobelpreis für Wirtschaftswissenschaften ziemlich schwer zu verdienen ist, da eine bestimmte wissenschaftliche Arbeit mit allen akademischen Kriterien in das wirkliche Leben passen muss und universelle Vorteile für zukünftige Generationen haben muss. Eine solche Innovation kann jedes Wirtschaftsmodell sein, das löst soziale Probleme wie Arbeitslosigkeit auf hohem Niveau.veröffentlicht:
BLUE Estimator
 Um während der Regressionsanalyse eine gültige Schlussfolgerung zu ziehen, muss das Modell die Gauß-Markov-Annahmen erfüllen, die in der folgenden Tabelle aufgeführt sind. Wenn diese Annahmen erfüllt sind, ist das von OLS (ordinary least squares) bewertete Modell am optimalsten. Daher entspricht das Akronym BLUE (Best Linear Unbiased Estimator) einer bestimmten Position, die auch als Gauß-Markov-Theorem bekannt ist.
Um während der Regressionsanalyse eine gültige Schlussfolgerung zu ziehen, muss das Modell die Gauß-Markov-Annahmen erfüllen, die in der folgenden Tabelle aufgeführt sind. Wenn diese Annahmen erfüllt sind, ist das von OLS (ordinary least squares) bewertete Modell am optimalsten. Daher entspricht das Akronym BLUE (Best Linear Unbiased Estimator) einer bestimmten Position, die auch als Gauß-Markov-Theorem bekannt ist.| Annahmen | i = 1,2, . . . , n und j = 1,2. . . , m |
|---|---|
| 1. Das Modell ist linear und das zufällige Element ist unabhängig von den erklärenden Variablen | Y = ꞵ0 + ꞵ1X1 + ꞵ2X2 + . . . + ꞵmXm |
| 2. der Mittelwert des zufälligen Mitglieds gleich Null | E(ui) = 0 |
| 3. Unabhängige Variablen und zufälliges Mitglied sind nicht korreliert | cov(ui,xj) = 0 |
| 4. Zufällige Elementvariation entspricht theoretischer Variation | D(ui) = 𝛔2(u) |
| 5. Zufällige Mitglieder sind unabhängig voneinander | E(uqup) = 0 , q ≠ p |
| 6. Der Rang der unabhängigen Variablenmatrix entspricht der Anzahl ihrer Spalten und ist geringer als die Anzahl der Beobachtungen | r(X) = m+1 < n |
| 7. Zufälliges Mitglied ist normal verteilt | Ui ~ N(0, 𝛔2(u)) |
veröffentlicht: